
Road Segmentation Project
computational intelligence lab eth course project
Abstract
The extraction of information from image and video is a challenging task in computer vision and machine learning. A concrete problem is locating and labeling objects in an image, for example during the conversion of satellite images to road maps. In theory, this allows map-services to enhance and update their images automatically by detecting new roads from updated satellite images as well as to notify of discrepancies between machine-generated and human-generated predictions. Factors such as large variances in road designs, lighting conditions, and occlusions make roads surprisingly challenging to categorize correctly. This project explores the use of various fully convolutional networks for labeling roads in RGB satellite images and concludes with the use of a modified U-Net to give reliable results for even a small data set of training images.
Setting
Given satellite images together with the labelled road positions, our task is to train a model capable of pixelwise predicting roads on satellite images. The available time was around 2 months in a group of 4 people.
Some Notes
Since we didn't have much data we relied heavily on perturbations. We used various types of elastic deformations of the input. Examples are rotations, image flipping, stretching in one or both axis and shearing of the images.
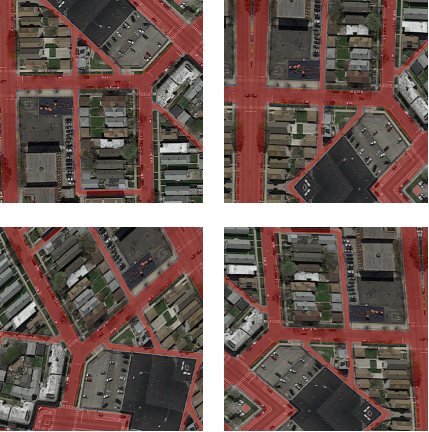
Augmentation example.
Finally we were able to achieve a pretty good result in segmenting roads.
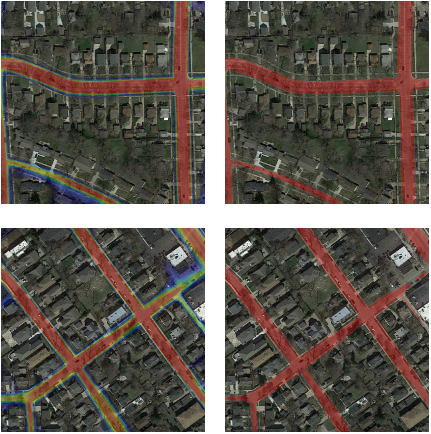
Network ouput after being trained on only 100 images. On the left we have the output probabilities as overlay over the input images. On the right the predicted roads using a probability cutoff of 0.6.
Report